
From time to time I read Pitchfork.com to get new music recommendations. Now, I’m no music snob. If it’s on the Top 40, it’s good enough for me. But Pitchfork’s music reviewers tend to be strong writers and extremely knowledgeable, so it can be really enlightening to get their perspective on a certain artist or album.
Recently, I came across a collection of over 18,000 music reviews scraped from Pitchfork on Kaggle. The possibilities for analyzing how Pitchfork writers write about music were too good to resist. Today I’ll walk you through how I modeled topics on the subset of reviews about music in the “Pop/R&B” genre. I’ve got some insights for you on who (according to Pitchfork) are the paragons of pop. Read on!
But first, EDA

EDA stands for Eccentric Disco Artist. Kidding! It’s Exploratory Data Analysis, and although the dataset has concise, clear documentation on Kaggle, we still need to do some so we know what we’re working with.
The data is presented in a sqlite database with tables containing the texts of the reviews themselves plus basic metadata on the reviews, artists, genres. etc. Each review has a unique identifier (reviewid) that can be used to easily join tables. For each reviewid, there is a single row in the main “reviews” table, but there may be multiple rows in the other tables to record multiple artists, genres, etc. associated with that review. So, for instance, a review of Black Messiah by D’Angelo and The Vanguard might have one record in the “reviews” table and two records in the “artists” table because D’Angelo and The Vanguard are considered separate artists.
All this means for my analysis is that a given review might pertain to more than one genre or artist, which can affect things like the counts of reviews per genre. This isn’t that big of a deal, but I just wanted to make it clear.
Let’s take a look at some basic visualizations.
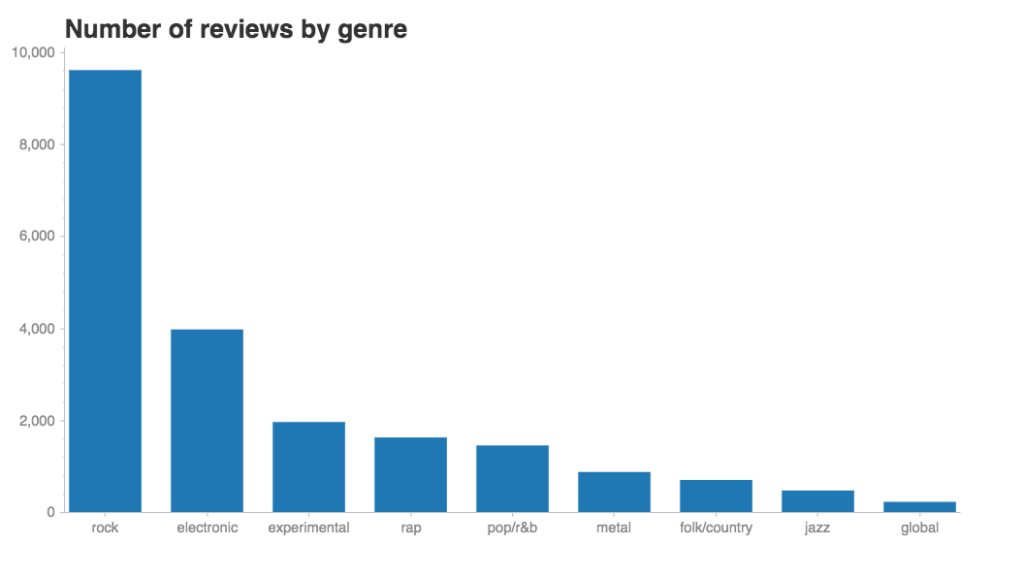
There are many more reviews of music in the “rock” genre than in any other. I don’t know anything about the history of Pitchfork, but this makes me wonder if it started out with a focus on rock and later expanded into other genres. (If you have some insight on this, hit me up in the comments.) I assume there’s also a pretty big bias here toward English-language music, despite the existence of a “global” category (but no “Latin” one).
Let’s take a look at how Pitchfork reviewers have rated music across all genres.
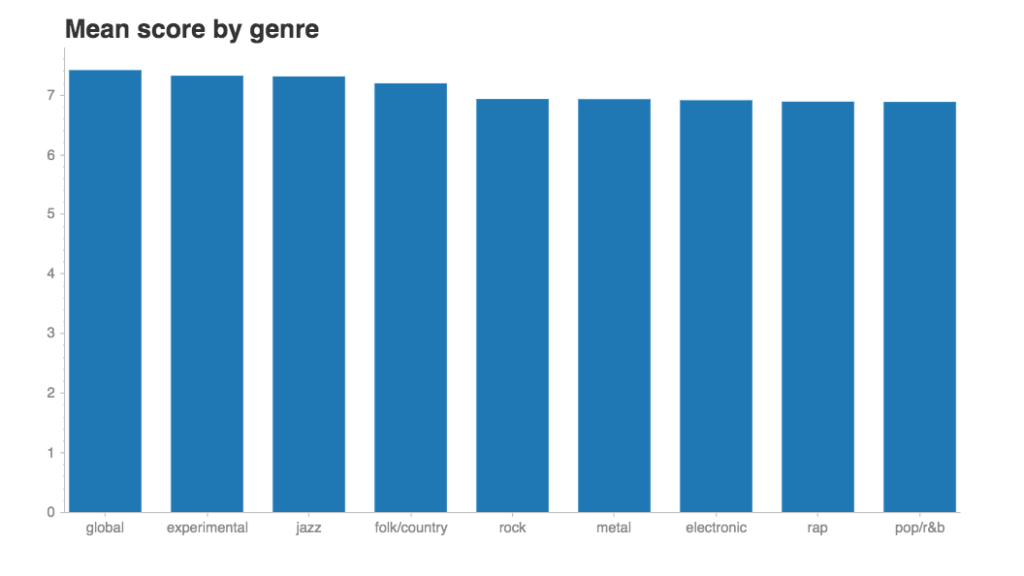
I can tell you that the mean score overall is 7.0 and the median is 7.2 (out of 10). There’s really not much difference in the mean score across classes, but I’m not surprised to see pop/r&b at the bottom. As a Pitchfork reader, I wouldn’t say that pop is the favorite genre of Pitchfork’s editorial board.
There’s another handy metric in this dataset, and that’s whether an album was designated “Best New Music.” This distinction is awarded sparingly. Across all genres, only 5% of albums or songs reviewed are “Best New Music.”
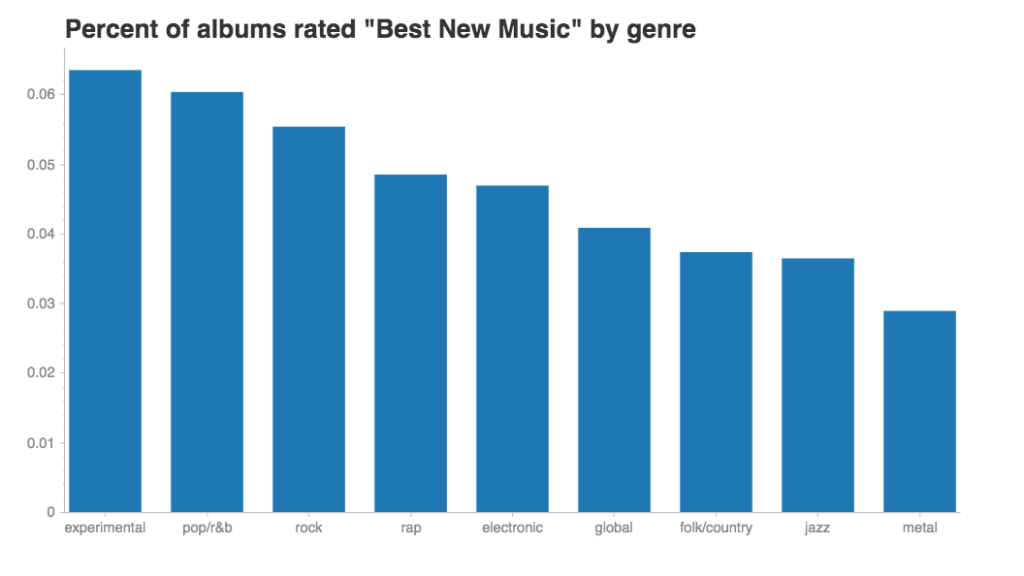
I’ll admit I was a little surprised to see pop/r&b second only to experimental for percent of albums rated “Best New Music.” Here I thought Pitchfork had a prejudice against pop; maybe I had a prejudice against Pitchfork!
From here on out, I’m going to focus on modeling topics in the 1,471 reviews in the pop/r&b genre.
Topic modeling, take 1
I wanted to try two different algorithms for topic modeling: Non-negative Matrix Factorization (NMF) and Latent Dirichlet Allocation (LDA). In the implementation below, each calculates topics using different input data (NMF takes TF-IDF vectors, LDA takes count vectors). I got the inspiration for how to implement these (and especially for how to print out the top words for each topic) from this demo in the scikit-learn documentation by Olivier Grisel, Lars Buitinck, and Chyi-Kwei Yau.
Here’s the code for a function to use NMF to model topics on the texts of reviews in the pop/r&b genre:
# Create a function to model topics using NMF
def nmf_it(data, n_features, n_components, n_top_words, stop_list):
'''Fits an NMF model and prints top words for each topic.
Dependencies: sklearn.feature_extraction.text.TfidfVectorizer,
sklearn.decomposition.NMF
Parameters:
data: DataFrame/Series containing only raw texts
n_samples: number of texts to sample from data
n_features: length of TF-IDF vectors to calculate
n_components: number of topics to model
n_top_words: number of words to print for each topic, ranked by
frequency
stop_list: your list of stopwords to remove
'''
# Import TfidfVectorizer and NMF
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import NMF
# Instantiate and fit TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer(max_df=0.95, min_df=2,
max_features=n_features,
stop_words=stop_list)
tfidf = tfidf_vectorizer.fit_transform(data)
# Fit the NMF model
nmf = NMF(n_components=n_components, random_state=1, alpha=.1,
l1_ratio=.5).fit(tfidf)
# View top words for each topic
print("\nTopics in NMF model:")
tfidf_feature_names = tfidf_vectorizer.get_feature_names()
for topic_idx, topic in enumerate(nmf.components_):
message = "Topic #{}: ".format(topic_idx+1)
message += " ".join([tfidf_feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1]])
print(message)
return tfidf, nmfTo use this function, just supply the review texts and specify how many topics and how many top words you want. Here I specify that I want TF-IDF vectors of length 1,000, 20 topics, and the top 10 words from each. Don’t forget to supply your own list of stop words to remove.
# View top 10 words for 20 topics
tfidf, nmf = nmf_it(data, 1000, 20, 10, stop_list)Here are the results:
Topics in NMF model:
Topic #1: like album one song songs even record time love much
Topic #2: rap rapper hip rappers hop mixtape rapping beats wayne raps
Topic #3: prince purple rain funk kiss sex new world guitar 80s
Topic #4: pop indie group girls girl love rock star stars madonna
Topic #5: disco dance mix house dj electro duo synth club remix
Topic #6: guitar acoustic piano vocals melody folk bass percussion drums electric
Topic #7: jones soul state old give soundtrack breaks strings mother james
Topic #8: björk live strings dirty disc box remixes quality melody mark
Topic #9: band rock bands indie sound go group guitars live punk
Topic #10: music jazz dance electronic musicians traditional modern house well listening
Topic #11: funk soul jazz hayes hip hop horn 70s groove horns
Topic #12: ep oh track year vocals original remixes summer future release
Topic #13: beyoncé rihanna jay star day album love singles dream co
Topic #14: gainsbourg french de melody english reggae air film death musical
Topic #15: robyn body talk dance free 2010 single love pop ready
Topic #16: black box brown badu soul even life women hell hop
Topic #17: diplo mix major mixtape la top dj reggae tape fire
Topic #18: taylor hot piano closing solo song emotional throughout instrumentation pieces
Topic #19: blake james bass piano 2011 samples last british vocal london
Topic #20: jackson michael wall rhythm disc video la oh dancing majorThere are some pretty relevant themes in there! I see topics devoted to related genres (rap, folk, jazz, rock). There are also some topics focused on artists with distinctive styles and widespread influence, the sorts of folks that less-famous artists might be compared to in a review.
I chose 20 topics arbitrarily, so now let’s investigate whether that was a good choice. Maybe we should combine some of those 20 topics or split them into even more specific topics. Because topic modeling is unsupervised learning, there’s no “right answer” to compare each topic assignment to, but we use some metrics to examine the fit of different numbers of clusters (topics) and see what works best.
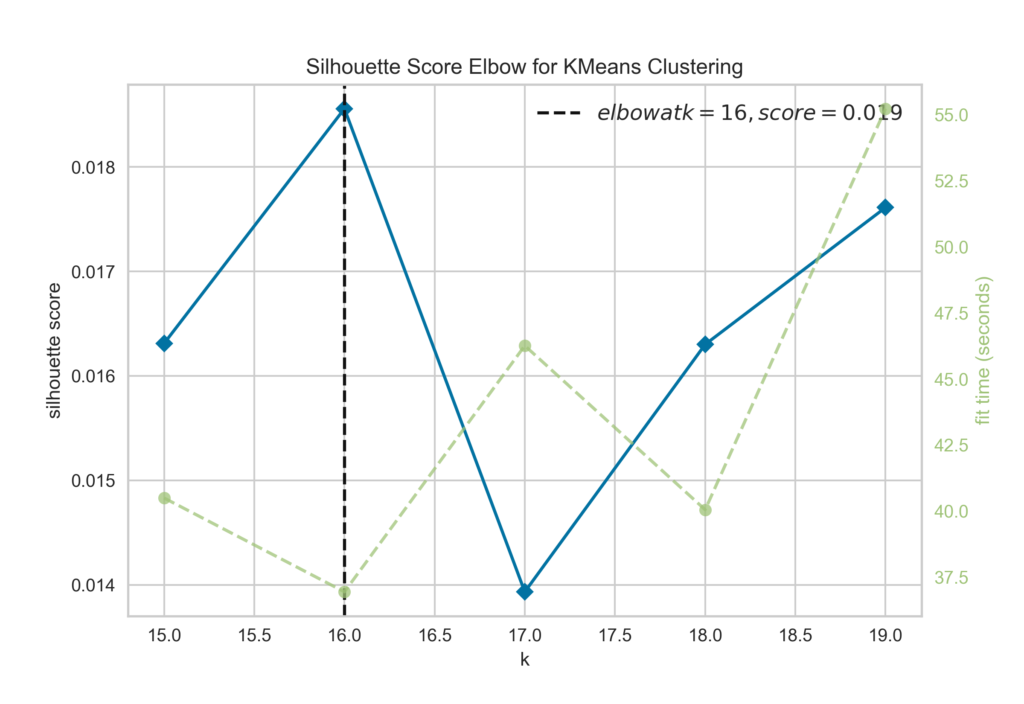
There are a couple of different metrics you can use to determine the best number of clusters to calculate with a clustering algorithm, and they usually focus on how dense the clusters are internally and how separate the clusters are from one another. Here I chose to use silhouette score, but keep in mind that there are other options. I used the Yellowbrick package to get a quick visualization of the silhouette score at various numbers of topics, calculated with a k-means algorithm and TF-IDF vectors. Here’s the code:
# Import needed objects
from sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizer
from sklearn.feature_extraction.text import TfidfVectorizer
# Vectorize the text sample
tfidf_vectorizer = TfidfVectorizer(max_df=0.95, min_df=2, max_features=1000, stop_words=stop_list)
tfidf = tfidf_vectorizer.fit_transform(data)
# Instantiate the KMeans model and visualizer
kmeans = KMeans(random_state=1)
visualizer = KElbowVisualizer(kmeans, k=(15, 25), metric='silhouette')
# Fit the visualizer and plot the results
visualizer.fit(tfidf)
visualizer.show()This prints out a handy graph that shows an elbow in the silhouette score at 16 clusters. That means we should consider 16 topics a good number to consider for this dataset, according to this metric. Whatever the reviewers are saying about pop/r&b music, it can be most tidily sorted into 16 topics.
Now that we know that 16 is a good number of topics to consider, let’s run the NMF algorithm again and see the results:
# View top 10 words for 16 topics
tfidf, nmf = nmf_it(data, 1000, 16, 10, stop_list)Topics in NMF model:
Topic #1: like album pop one song songs love record even time
Topic #2: rap rapper hip hop rappers mixtape rapping beats wayne lil
Topic #3: prince purple rain funk kiss sex new world guitar 80s
Topic #4: beyoncé rihanna jay pop star girl album singles love day
Topic #5: disco dance mix dj house electro duo synth club remix
Topic #6: guitar acoustic piano vocals melody folk bass percussion drums guitars
Topic #7: jones soul state old give soundtrack strings breaks mother albums
Topic #8: björk live strings dirty disc box remixes quality melody mark
Topic #9: band rock bands indie sound group go guitars live punk
Topic #10: music jazz dance electronic musicians traditional modern house well people
Topic #11: funk soul jazz hayes hip hop horn 70s groove horns
Topic #12: blake james bass piano ep 2011 samples last vocal british
Topic #13: jackson michael wall rhythm la major disc video dancing oh
Topic #14: gainsbourg french de melody english reggae air film death musical
Topic #15: robyn body talk pop dance free 2010 love single ready
Topic #16: black box brown badu soul even life women hell hopIt looks like we shed some of the less-specific topics and kept those pertaining to other major genres and prominent artists. Nice!
Now let’s try the same process again, but with LDA instead of NMF.
Topic modeling, take 2
The only big difference when modeling topics with LDA is that I’m going to use count vectors instead of TF-IDF vectors as the input. I made another function, very similar to the one above, to perform the clustering and print the top words for each topic. Take a look:
# Create a function to model topics using NMF
def lda_it(data, n_features, n_components, n_top_words, stop_list):
'''Fits an LDA model and prints top words for each topic.
Dependencies: sklearn.feature_extraction.text.CountVectorizer,
sklearn.decomposition.LatentDirichletAllocation
Parameters:
data: DataFrame/Series containing only raw texts
n_samples: number of texts to sample from data
n_features: length of TF-IDF vectors to calculate
n_components: number of topics to model
n_top_words: number of words to print for each topic, ranked by
frequency
stop_list: your list of stopwords to remove
'''
# Import TfidfVectorizer and NMF
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
# Instantiate and fit TfidfVectorizer
count_vectorizer = CountVectorizer(max_df=0.95, min_df=2,
max_features=n_features,
stop_words=stop_list)
counts = count_vectorizer.fit_transform(data)
# Fit the LDA model
lda = LatentDirichletAllocation(n_components=n_components,
max_iter=5,
learning_method='online',
learning_offset=50.,
random_state=0).fit(counts)
# View top words for each topic
print("\nTopics in LDA model:")
counts_feats = count_vectorizer.get_feature_names()
for topic_idx, topic in enumerate(lda.components_):
message = "Topic #%d: " % topic_idx
message += " ".join([counts_feats[i] for i in topic.argsort()[:-n_top_words - 1:-1]])
print(message)
return counts, ldaAnd here’s what happens when I called this function for the same 1,471 reviews, asking for vectors of length 1,000, 20 topics, and the top 10 words for each topic:
# View top 10 words for 20 topics
lda_it(data, 1471, 1000, 20, 10, stop_list)Topics in LDA model:
Topic #1: like rock band pop music songs sound one tracks many
Topic #2: like band songs much new whose record even debut good
Topic #3: like album one pop music song songs even time much
Topic #4: like songs one album even music good life two pop
Topic #5: rock album like drum many songs voice us indie bit
Topic #6: one like songs album pop love song music work record
Topic #7: album time pop double track like one night music first
Topic #8: björk dj house even strings percussion remix series mark like
Topic #9: like album even band first record rock love one vocals
Topic #10: like track album third one old three music though record
Topic #11: prince blake jones album purple like new song rain funk
Topic #12: album like time listening one sound much music soul first
Topic #13: smith one hour lonely lyrics record good album la like
Topic #14: road low like read even high music one perhaps good
Topic #15: robyn album pop talk prince body world first rain around
Topic #16: love like album songs song music one soul new voice
Topic #17: hayes oh ocean album remixes like sound voice songs band
Topic #18: band like album guitar music rock pop sound one songs
Topic #19: wayne lil mixtape rapper whether god best raps new drama
Topic #20: like pop album songs song music new band prince timeRight away, these topics look different than the ones calculated using NMF. Since LDA uses count vectors, we see common words (like, album, songs) turning up all over the place. Some of these topics make sense given what we know about the pop/r&b genre, like #19 (rap, Lil Wayne) or #15 (Robyn, Body Talk). But most of them are just too generic to be meaningful.
I could go through the same process as above to select the best number of topics/clusters and rerun the LDA algorithm, but I’ll spare you. For this dataset, NMF produced results that seem much more meaningful.
Next, let’s take a closer look at a topic near and dear to me: Robyn.
Drawing connections
I love me a pop princess, and Robyn holds a special place in my heart for her dance vibes, electronic influences, and, of course, amazing hairstyles over the years. Pitchfork writers must have a lot to say about her, too, since she comes up as almost a topic of her own in my models above. Because her name is the top word in topics in both the NMF and LDA models, we know that her name is both frequently occurring (has a high value in the count vectors used in LDA) and likely to be thematically important (has a high value in the TF-IDF vectors used in NMF). She’s kind of a big deal!
Robyn’s work has been reviewed seven times in Pitchfork. Here’s a rundown:

Some key points from the table above:
- Her average score (on a 10-point scale) is 8.0, compared to an average of 6.8 across all pop/r&b artists.
- In two reviews her work was designated “Best New Music.” That’s 29% of her reviews, which puts her somewhere around the 93rd percentile among pop artists.
In a crowded sky of pop stars, she dances on her own. She’s so awesome, in fact, that her name comes up a lot in reviews of other pop artists, including:
- Ariana Grande
- Charli XCX
- Icona Pop
- Jessie J
- Lykke Li
- Sia
- Tove Lo
- Kleerup
- La Bagatelle Magique
- Nina Sky
- Metronomy
- Pandr Eyez
- Röyksopp
- The Lonely Island
- Zhala
The usual application of topic modeling is to generate a categorical variable (like genre) that we can then use for modeling or prediction. It’s basically a strategy for turning an unsupervised learning problem into a supervised one. In the case of music reviews, we could build a model that includes our topics as a feature to classify new reviews according to subject matter.
If we wanted to take this analysis in another direction, we could build a network graph where the nodes represented artists and the edges represented co-occurrence of two artists’ names in a review. This would help us understand where Pitchfork writers see similarities and differences among artists, and where they may be identifying sub-genres within pop/r&b. We could compare the topics we generated to our network graph to see if they identify the same key players in the pop/r&b world.
Now call your girlfriend
…and tell her how much you enjoyed this article.
H/t to Pitchfork for creating all these music reviews in the first place, Nolan Conaway for making them easy to use, and Grisel, Buitinck, and Yau for useful code snippets.