Some e-commerce sites let customers write reviews of their products, which other customers can then browse when considering buying a product. I know I’ve read product reviews written by my fellow customers to help me figure out if a product would be true to size, last a long time, or contain an ingredient I’m concerned about.
What if a business could predict which reviews its customers would find helpful? Maybe it could put those reviews first on the page so that readers could get the best information sooner. Maybe the business could note which topics come up in those helpful reviews and revise its product descriptions to contain more of that sort of information. Maybe the business could even identify “super reviewers,” users who are especially good at writing helpful reviews, and offer them incentives to review more products.
Using a large collection of product reviews from Amazon, I trained a range of machine learning models to try to identify which reviews readers rated as “helpful.” I tried Random Forests, logistic regression, a Support Vector Machine, GRU networks, and LSTM networks, along with a variety of natural language processing (NLP) techniques for preprocessing my data. As it turns it, predicting helpful reviews is pretty hard, but not impossible! To go straight to the code, check out my GitHub repo. To learn more about how I did it, read on.
The dataset
Here’s what you need to know about the dataset:
- It comes from Amazon (via Kaggle), in particular the food department, which includes not just food products, but also kitchen gadgets and pet foods.
- It was collected between 2002 and 2012, so it’s not exactly up to date, but I think there’s still plenty we can learn from it in 2020.
- It included over 500,000 reviews, and after I eliminated duplicates, 393,579 reviews remained.
- Readers had the opportunity to mark a review as “helpful” or not. There was also an option to downvote reviews, but it wasn’t used much. About 52% of the reviews received zero “helpful” votes, and the rest received one or more “helpful” votes.
- Besides “helpfulness” and the text of the review itself, the dataset also records the product ID, user ID, a timestamp, and the star rating (out of 5) the review-writer gave the product.
Here’s a quick look at the counts of reviews, total tokens, and unique tokens by class:
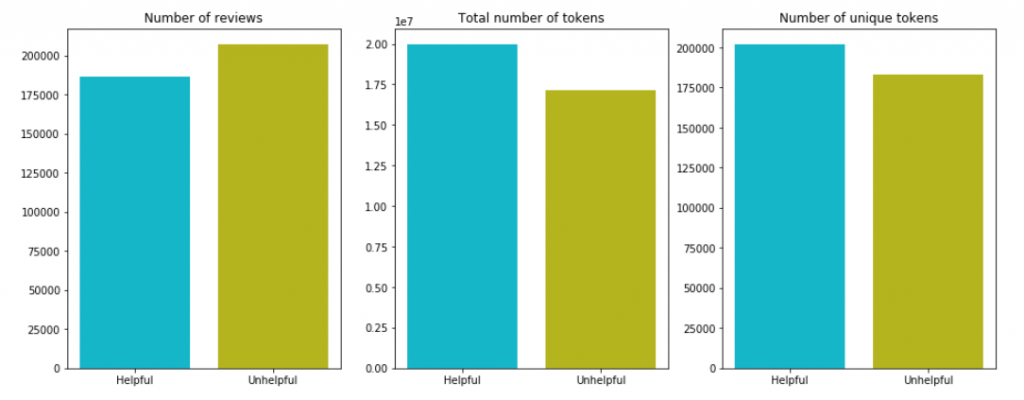
Although there are fewer helpful reviews, they contain more words and more unique words than the unhelpful ones.
Puzzling over prediction
Given the contents of this dataset, I had two big questions. Question 1: Can “helpfulness” be predicted using any of the features other than the text of the reviews themselves? For instance, if helpful reviews always include a 5-star rating or are always written by the same subset of reviewers, that would save me a lot of text-wrangling!
As it turns out, no: helpful reviews can’t be predicted using any of the other features in the dataset, or any of a handful that I engineered myself. Helpful reviews can be short, long, positive, or negative; they can be written by newbie or experienced reviewers; they can be about popular or obscure products; and their vocabulary is very similar to that of unhelpful reviews.
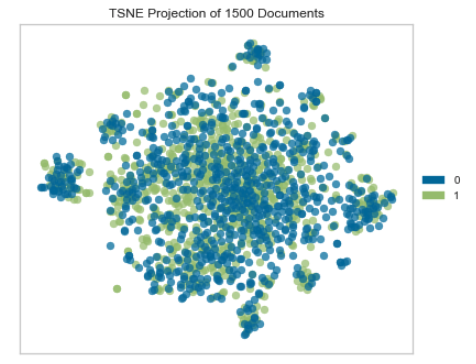
Here’s a t-SNE plot of a sample of reviews, focusing on the texts themselves. A t-SNE plot basically does principal components analysis on a dataset, reduces all the features to just 2 or 3 components, and plots them so you can see how the classes overlap (or don’t). This plot reveals a nightmare: at least in these two dimensions, the two classes overlap a lot.
That brings me to Question 2: If there’s no shortcut way to predict helpfulness, how should I go about predicting it from text? How should I preprocess the reviews for modeling? What models should I try? Using human-generated text as input for predictive models is notoriously difficult, partly because there are so many ways to turn text into data, and then you need fairly complex models to handle that data. Which to choose?
When deciding how to preprocess the review texts, I wanted to try a range of techniques, focusing on those that seemed most promising during the exploratory phase of my project. As for modeling, I wanted to start with models that were simpler and quicker to train, then work up to my most complex options. I hoped that the first few rounds of testing would help me identify the best preprocessing option, while the last few rounds would help me hone my best model.
Phase 1: Into the woods
My first big round of experimentation consisted of testing different preprocessing techniques against a baseline Random Forest model:
- Processed the text as bigrams, then trained a Random Forest on them.
- Processed the text as a term-document matrix (basic count vectorization), then trained a Random Forest on that.
- Calculated TF-IDF (term frequency-inverse document frequency) vectors, then ran those through a Random Forest.
All of these performed in the range of 54-55% accuracy on validation data, which is only a pinch better than random guessing, but at least it’s not worse than random guessing! TF-IDF scored the highest, so I decided to try to tune a Random Forest to do even better with TF-IDF vectors as input. I tried the following:
- Used a grid search to identify the best number of estimators and maximum depth of tree to use.
- Doubled the length of the TF-IDF vectors (i.e., created a lot more input data), then did a form of principal components analysis (using TruncatedSVD) to select a number of components that would explain 80% of the variance in the training data.
- Trained a final Random Forest using all the stuff I generated in the previous two steps.
All this yielded a model that was overfit to the training data (over 99% accuracy) and 57% accurate on validation data, my best so far.
But 7 percentage points better than random guessing isn’t much to write home about, so I moved on to a transfer learning approach.
Phase 2: GloVes off
Transfer learning involves taking weights calculated by someone else’s model and plugging them into your own. This can be a really convenient way to benefit from someone else’s investment in training a huge model on, for example, all of Wikipedia.
That’s where GloVe embeddings come in. Some smart folks at Stanford trained a massive model to quantify the relationships between English words in context. I can benefit from this by collecting the relevant embedding vector from GloVe for every word in my review corpus. Then for every review, I take the mean of all the individual word vectors to make a new vector that represents the whole text of the review. All the review vectors can then be passed to a model for training or prediction.
I passed my GloVe embeddings to three models: a Random Forest, a logistic regression, and a Support Vector Classifier. These models also scored in the range of 53-56% accuracy on validation data, with the Random Forest doing the best. After some additional tuning, I was still only getting a validation accuracy of 56%.
After all this, I was pretty keen to see what a neural network could do.
Phase 3: Nothing but nets
Sequence-to-sequence models are known to perform well with text data, so I decided to try a couple different neural network architectures of this type. I was especially interested in having these networks calculate their own embeddings on the fly; since GloVe hadn’t done so well, I hoped that embeddings based only on my dataset might be a better choice.
Have a look at the structure of my baseline neural network:
# Try again with more epochs, callbacks
import tensorflow as tf
embedding_size = 128
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Embedding(200000, embedding_size, input_shape=(100,)))
model.add(tf.keras.layers.GRU(25, return_sequences=True, input_shape=(100,)))
model.add(tf.keras.layers.GRU(25, return_sequences=True, input_shape=(100,)))
model.add(tf.keras.layers.GlobalMaxPool1D())
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(50, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(50, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(1, activation='relu'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=50, batch_size=2048, validation_data=(X_val, y_val))That’s a layer to calculate embeddings, two layers of 25 Gated Recurrent Unit (GRU) nodes each, a layer to pool their outputs, two dense layers of 50 nodes each (with 50% dropout to try to avoid overfitting), and then a single node to make the final prediction for each sample. I also tried the same architecture but with Long Short-Term Memory (LSTM) nodes instead of GRUs. There was no substantial difference in the results, and the GRUs were a little faster, so I decided to continue tuning the GRU network with bigger input vectors and more training epochs.
Best model and results
Overall, my best model was the last one: a GRU network achieving 59% accuracy on validation data. On my holdout dataset, this model scored 59% accuracy as well, which is not bad, considering the complexity of the problem it’s trying to solve.
A model like this could be used to sort reviews as they are submitted and move those likely to be helpful to the top of the queue. A business could also scrape its own website for reviews, filter for the helpful ones, and then review those to learn what potential customers want to know that their product descriptions aren’t providing. Likewise, a business could identify the writers of helpful reviews and encourage them to write more, or modify their review submission form to include tips for writing more informative reviews (as AirBnB, TripAdvisor, and others already do).
If you’d like to see my whole project on helpful reviews in glorious detail, check out the code on GitHub. Thanks for reading!